Publications
Selected research papers from MILab
* Equal Contribution ·
† Co-Corresponding Author
2026
Seeing Through Touch: Tactile-Driven Visual Localization of Material Regions
Seongyu Kim, Seungwoo Lee, Hyeonggon Ryu, Joon Son Chung, Arda Senocak†
CVPR 2026 († Corresponding Author)
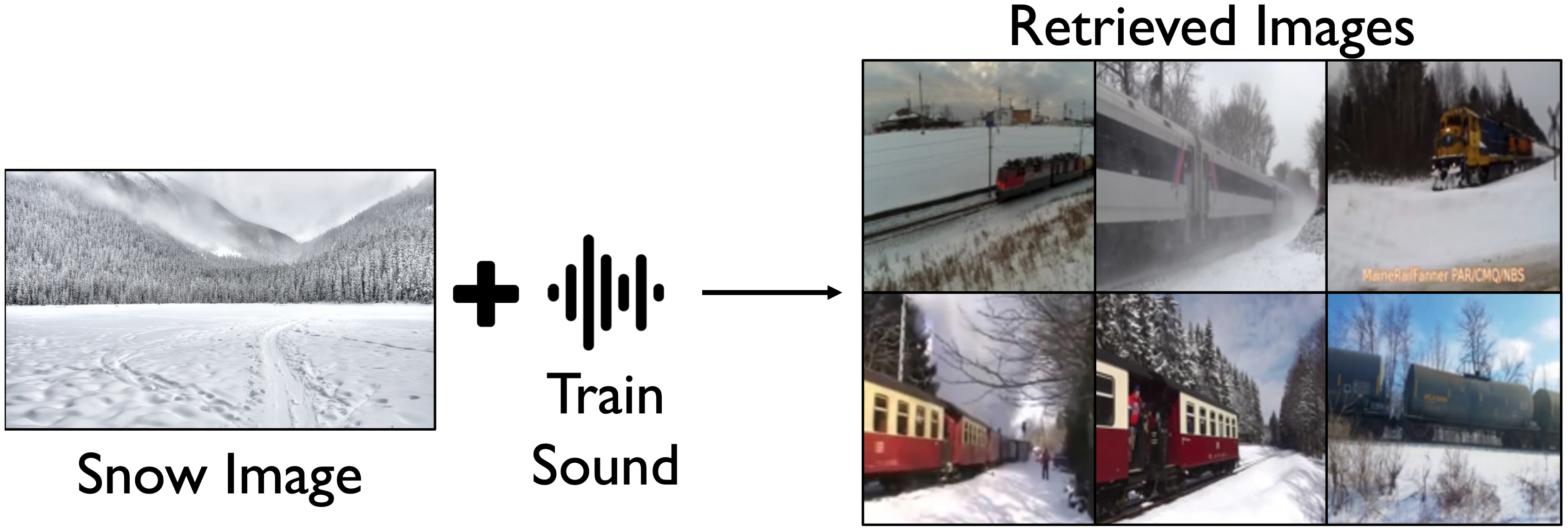
How Far Can We Go With Synthetic Data for Audio-Visual Sound Source Localization?
Arda Senocak*, Sooyoung Park*, Tae-Hyun Oh, Joon Son Chung.
CVPR 2026 Selected as Highlight Paper ⭐ (* Equal Contribution)
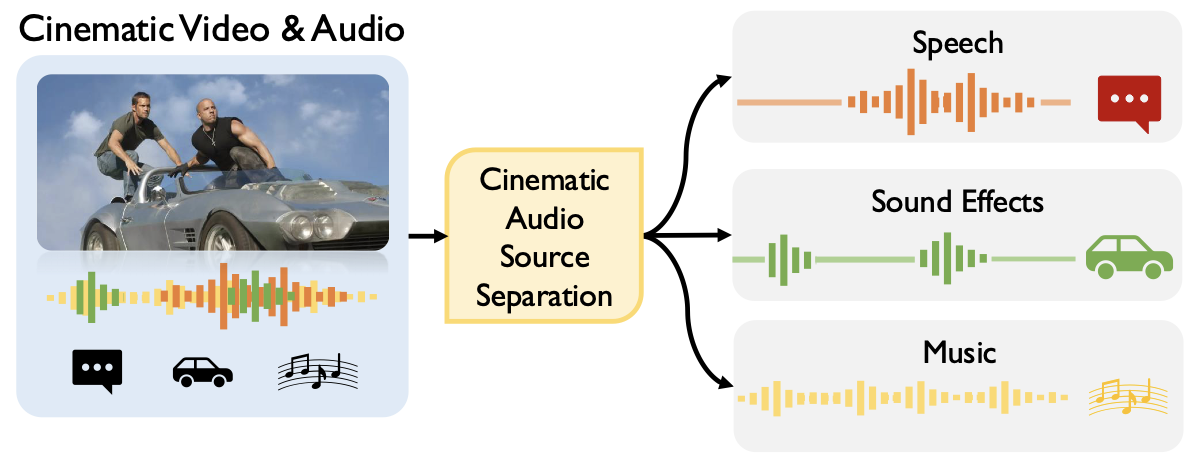
Cinematic Audio Source Separation Using Visual Cues
Kang Zhang*, Suyeon Lee*, Arda Senocak†, Joon Son Chung†
CVPR 2026 († Co-Corresponding Author)
2025
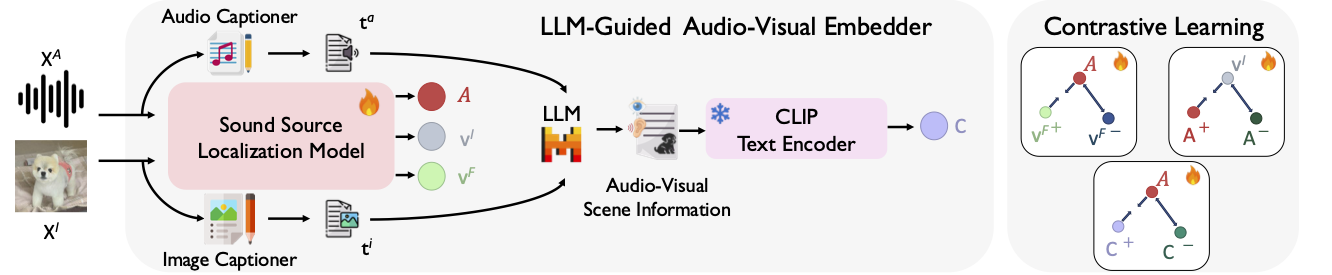
Hearing and Seeing Through CLIP: A Framework for Self-Supervised Sound Source Localization
Sooyoung Park*, Arda Senocak*, Joon Son Chung
IJCV 2025 (* Equal Contribution)
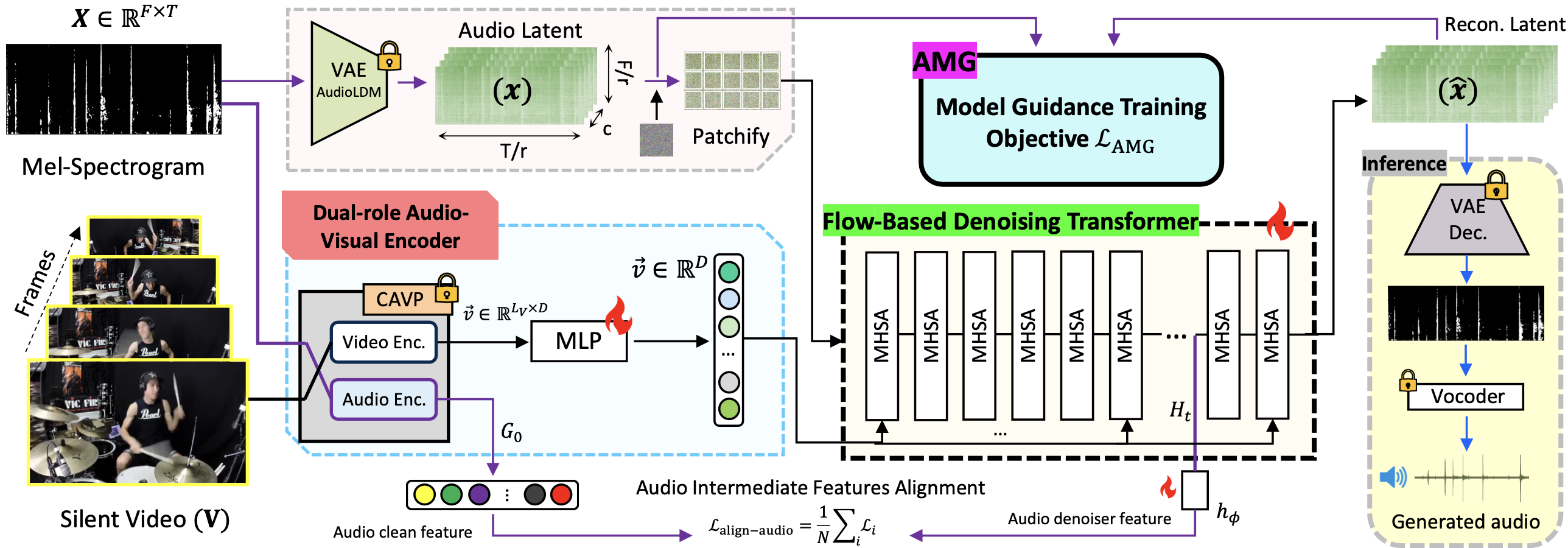
Model-Guided Dual-Role Alignment for High-Fidelity Open-Domain Video-to-Audio Generation
Kang Zhang*, Trung X. Pham*, Suyeon Lee, Axi Niu, Arda Senocak, Joon Son Chung
NeurIPS 2025
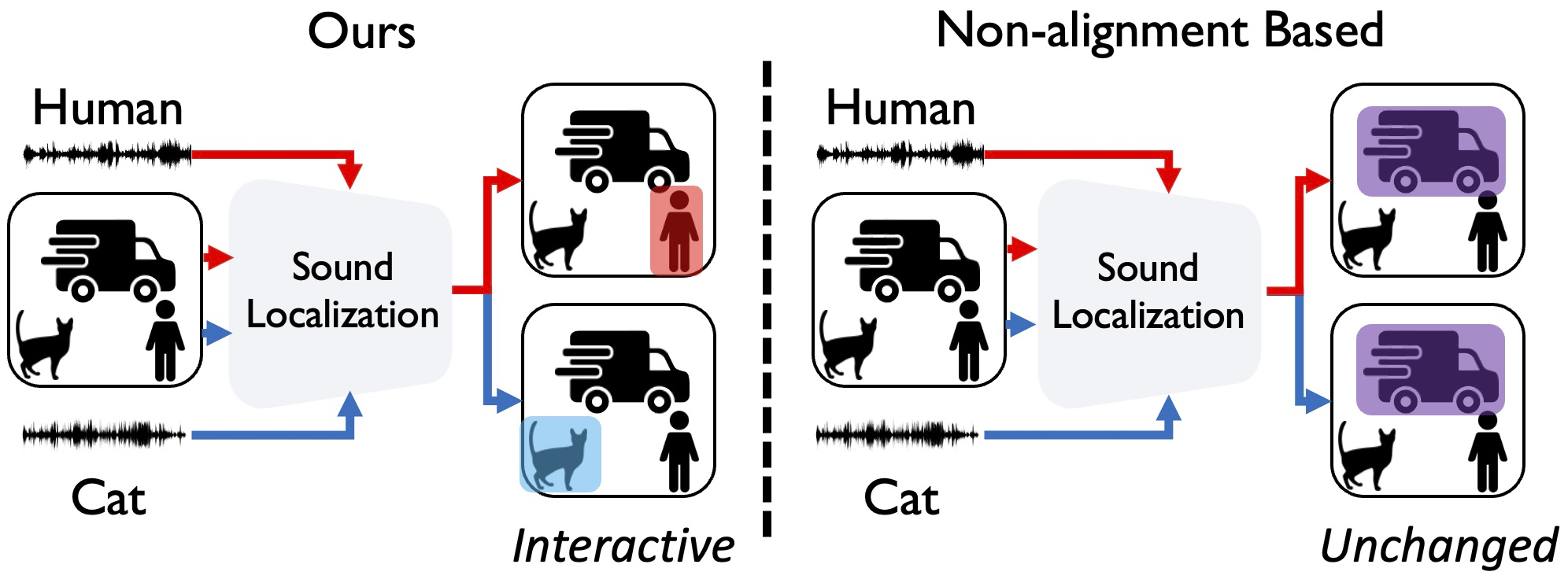
Aligning Sight and Sound: Advanced Sound Source Localization Through Audio-Visual Alignment
Arda Senocak*, Hyeonggon Ryu*, Junsik Kim*, Tae-Hyun Oh, Hanspeter Pfister, Joon Son Chung
TPAMI 2025 (* Equal Contribution) Impact Factor: 20.8
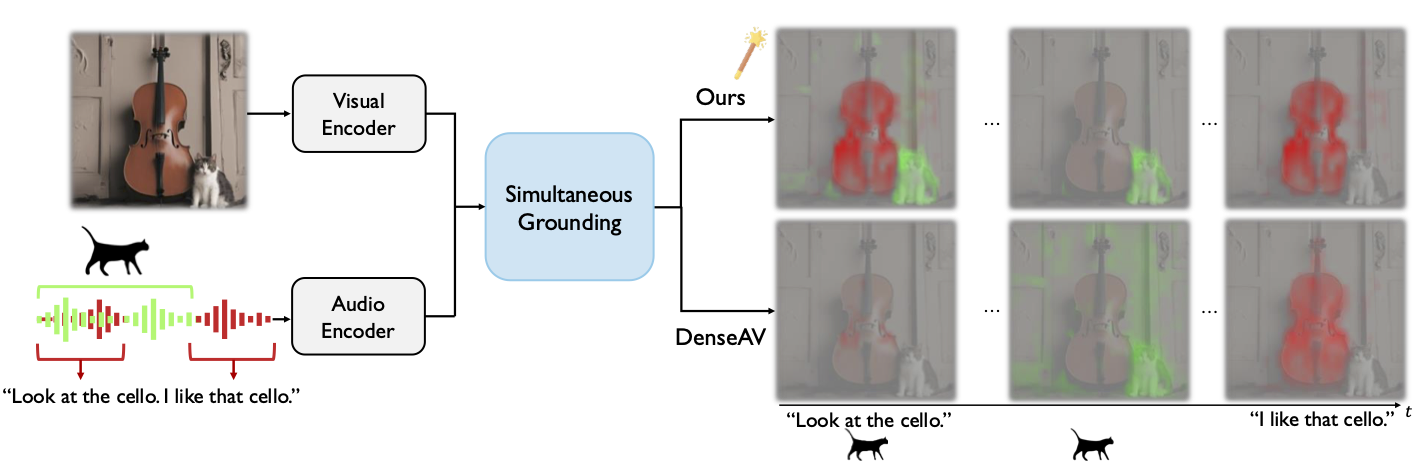
Seeing Speech and Sound: Distinguishing and Locating Audios in Visual Scenes
Hyeonggon Ryu*, Seongyu Kim*, Joon Son Chung, Arda Senocak†
CVPR 2025 († Corresponding Author)
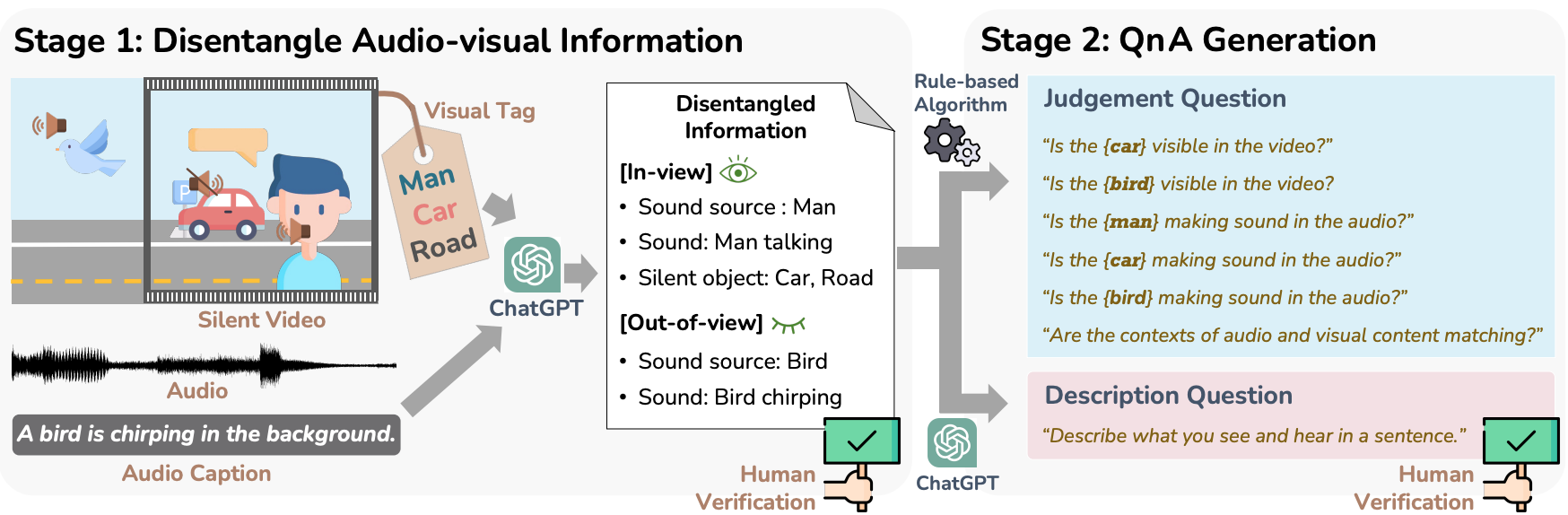
AVHBench: A Cross-Modal Hallucination Benchmark for Audio-Visual Large Language Models
Sung Bin Kim*, Hyun-Bin Oh*, JungMok Lee, Arda Senocak, Joon Son Chung, Tae-Hyun Oh
ICLR 2025
2024
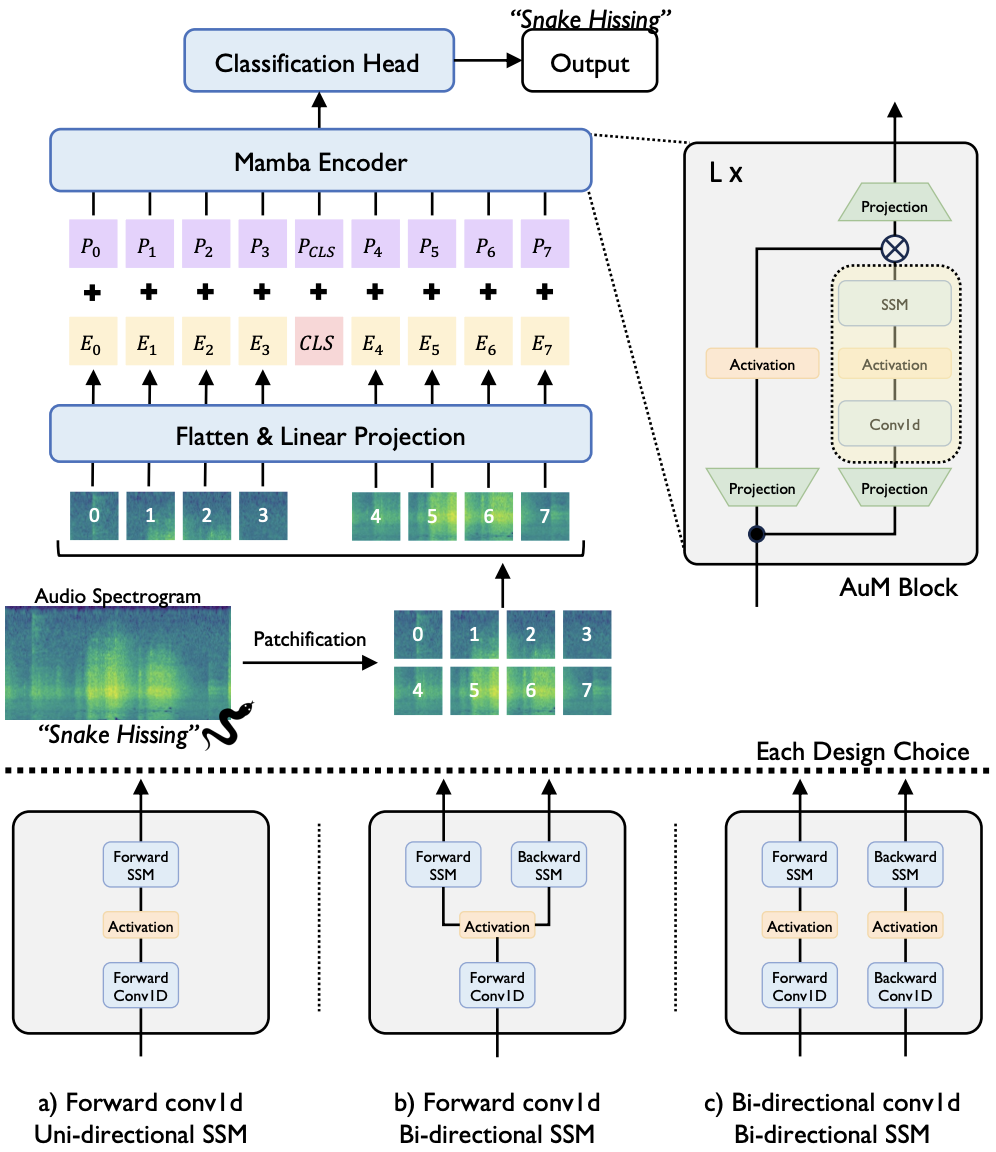
Audio Mamba: Bidirectional State Space Model for Audio Representation Learning
Mehmet Hamza Erol*, Arda Senocak*, Jiu Feng, Joon Son Chung
IEEE SPL 2024 (* Equal Contribution)
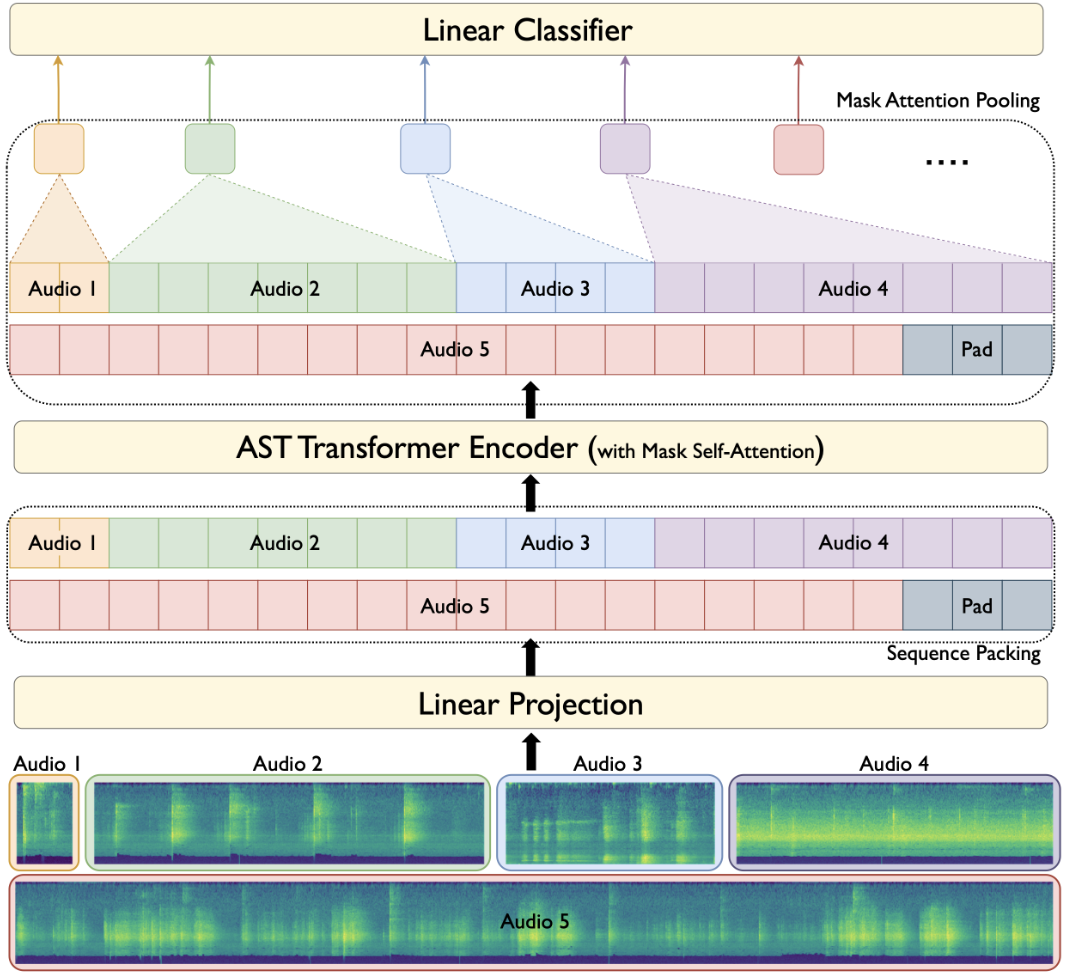
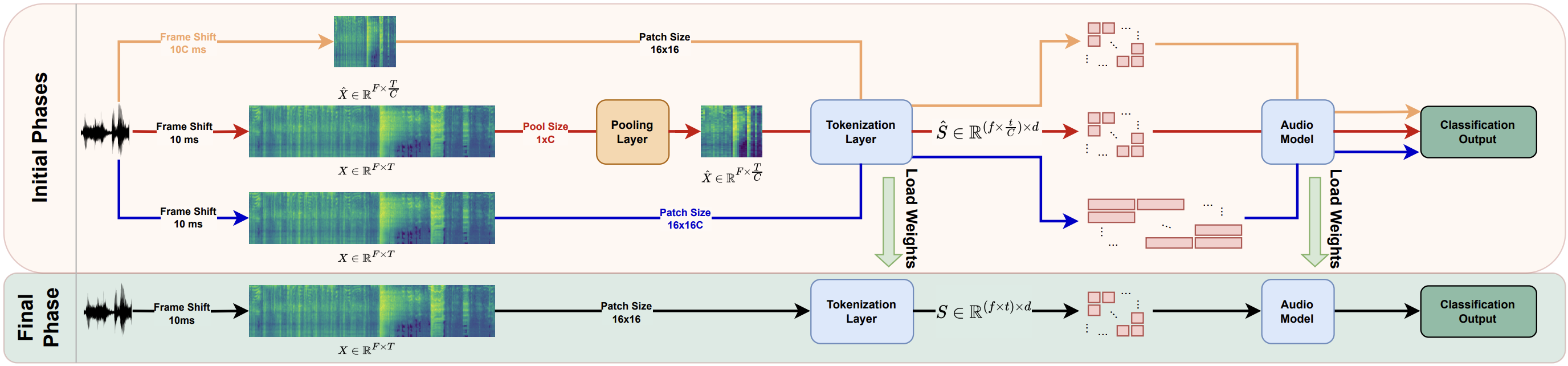
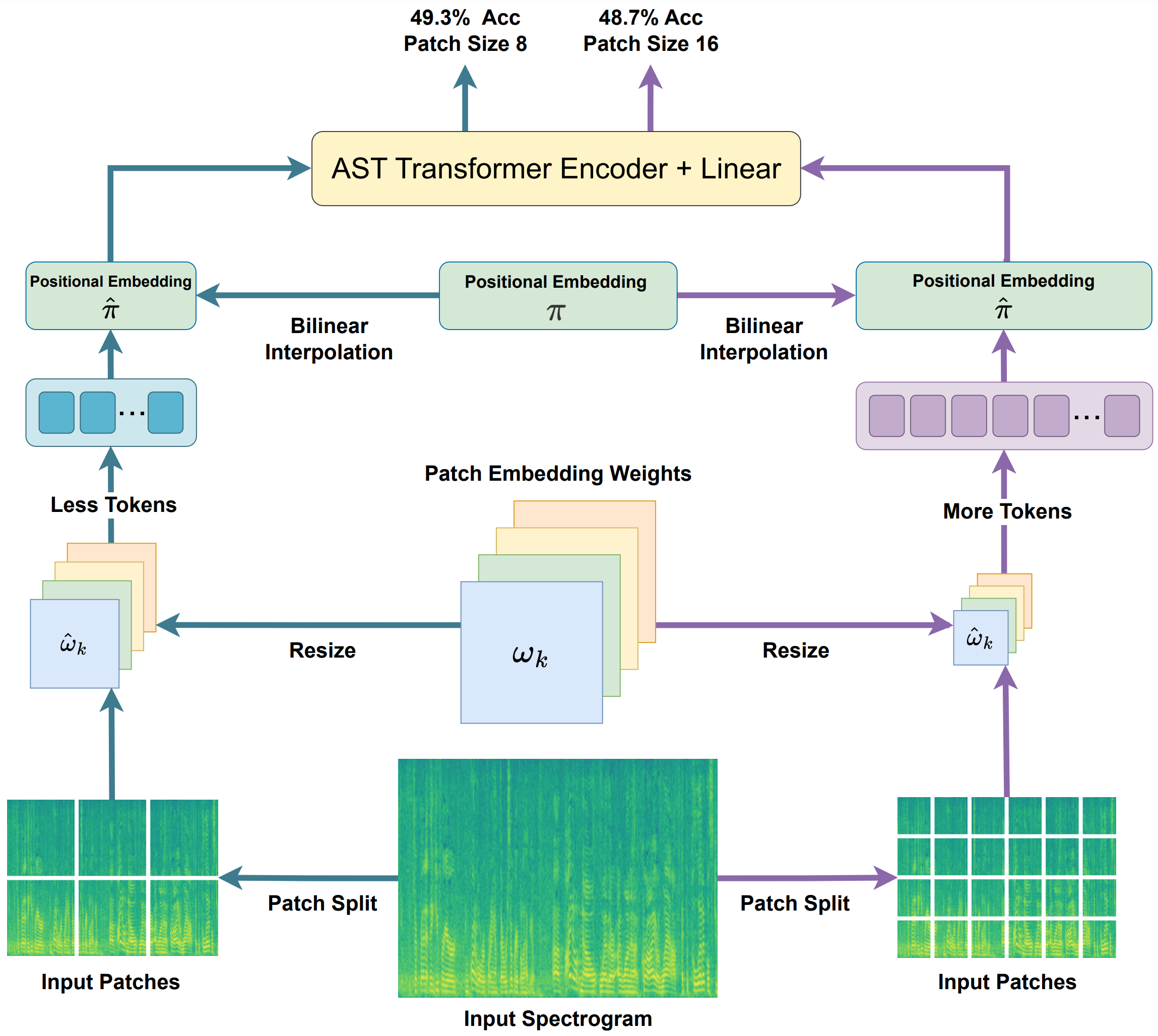
ElasticAST: An Audio Spectrogram Transformer for All Length and Resolutions
Jiu Feng, Mehmet Hamza Erol, Joon Son Chung, Arda Senocak†
Interspeech 2024 († Corresponding Author)
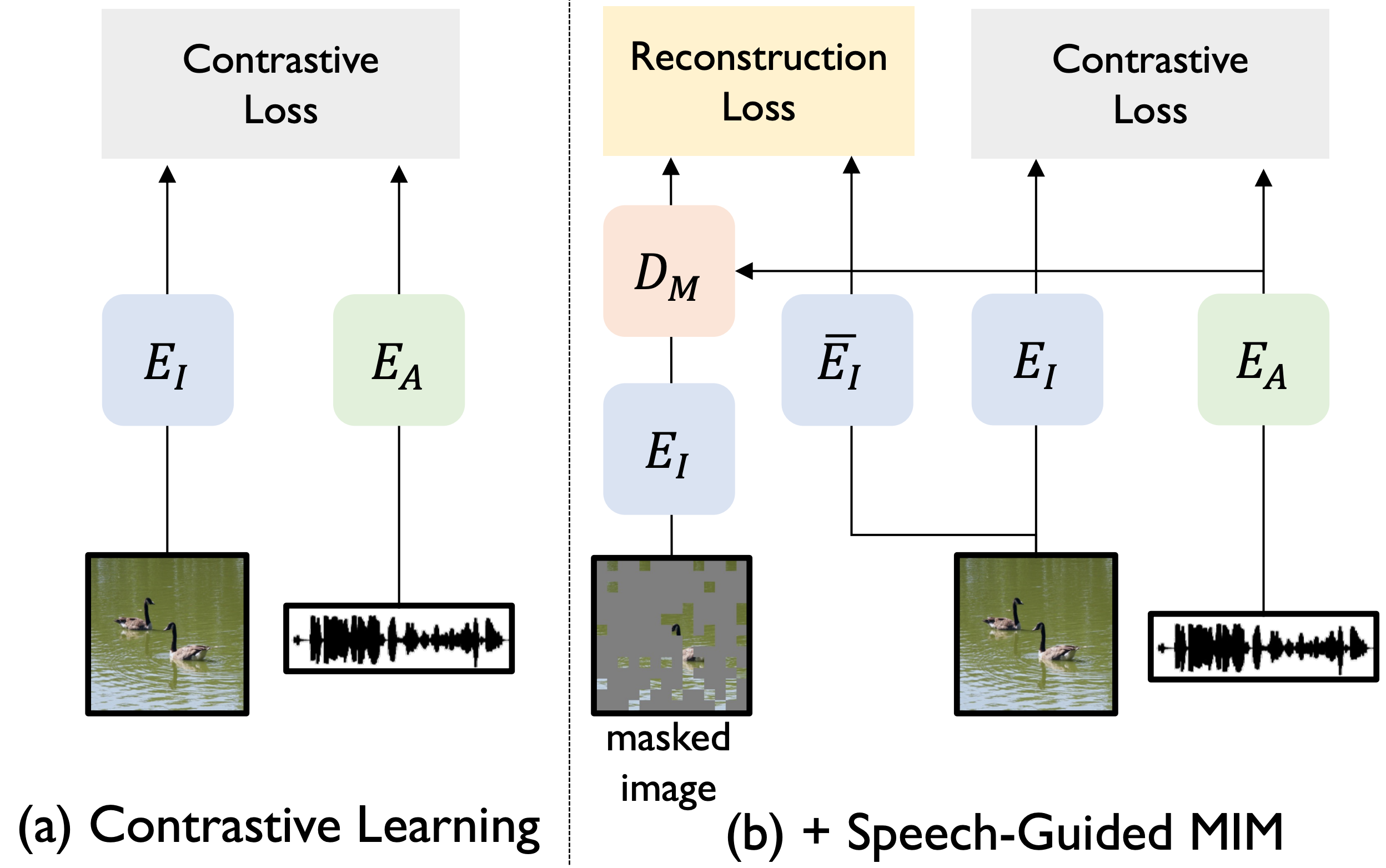
Speech Guided Masked Image Modeling for Visually Grounded Speech
Jong-Bin Woo, Hyeonggon Ryu, Arda Senocak, Joon Son Chung
ICASSP 2024
From Coarse to Fine: Efficient Training for Audio Spectrogram Transformers
Jiu Feng*, Mehmet Hamza Erol*, Joon Son Chung, Arda Senocak†
ICASSP 2024 († Corresponding Author)
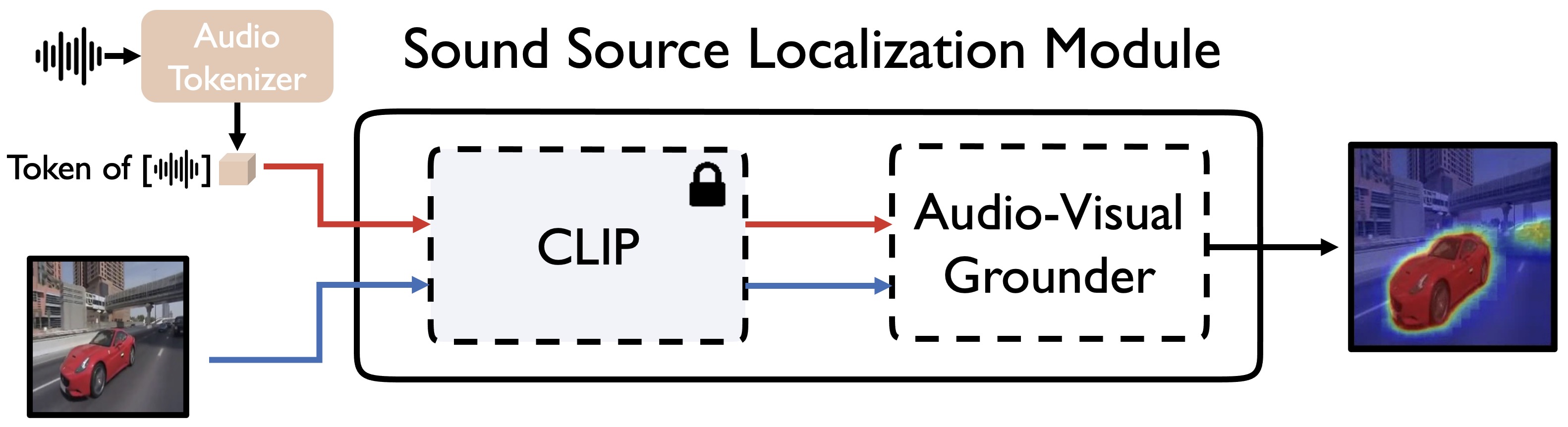
Can CLIP Help Sound Source Localization?
Sooyoung Park*, Arda Senocak*, Joon Son Chung
WACV 2024 (* Equal Contribution)
2023
Sound Source Localization is All about Cross-Modal Alignment
Arda Senocak*, Hyeonggon Ryu*, Junsik Kim*, Tae-Hyun Oh, Hanspeter Pfister, Joon Son Chung
ICCV 2023 (* Equal Contribution)
FlexiAST: Flexibility is What AST Needs
Jiu Feng*, Mehmet Hamza Erol*, Joon Son Chung, Arda Senocak†
Interspeech 2023 († Corresponding Author)
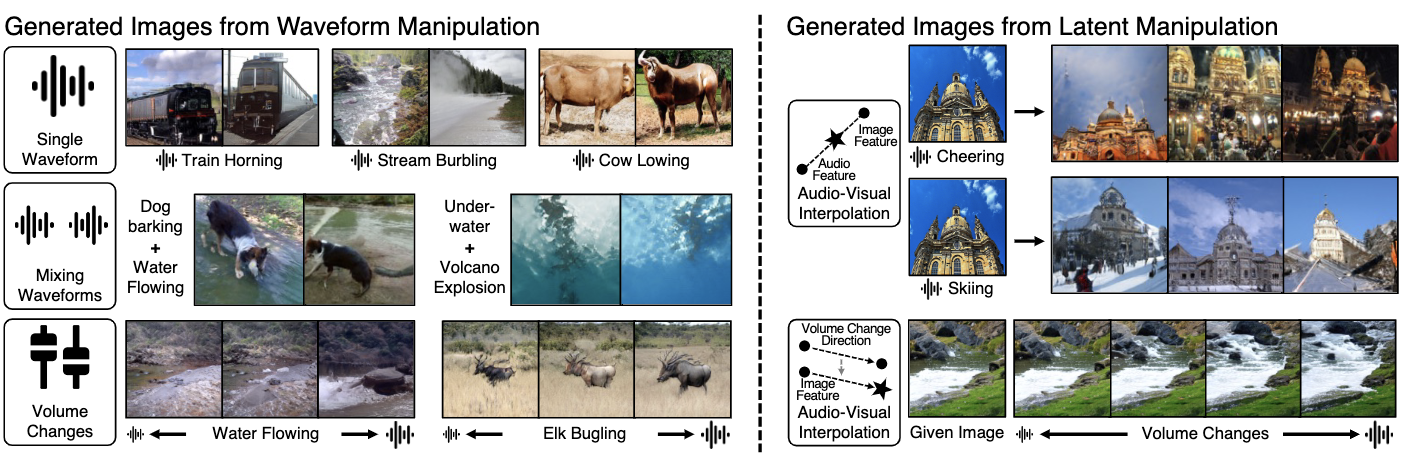
Sound to Visual Scene Generation by Audio-to-Visual Latent Alignment
Sung Bin Kim, Arda Senocak, Hyunwoo Ha, Andrew Owens, Tae-Hyun Oh
CVPR 2023
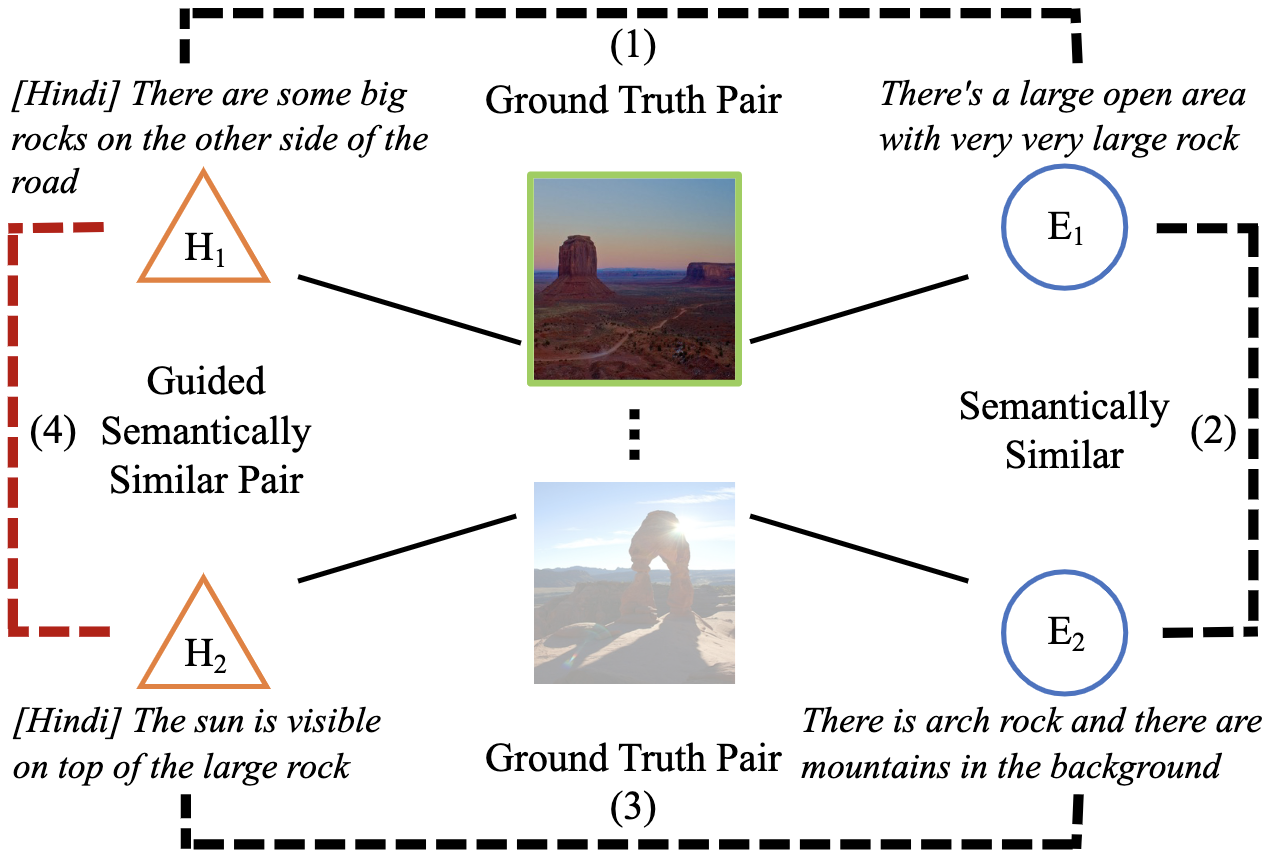
Hindi As a Second Language: Improving Visually Grounded Speech with Semantically Similar Samples
Hyeonggon Ryu*, Arda Senocak*, In So Kweon, Joon Son Chung
ICASSP 2023 (* Equal Contribution)
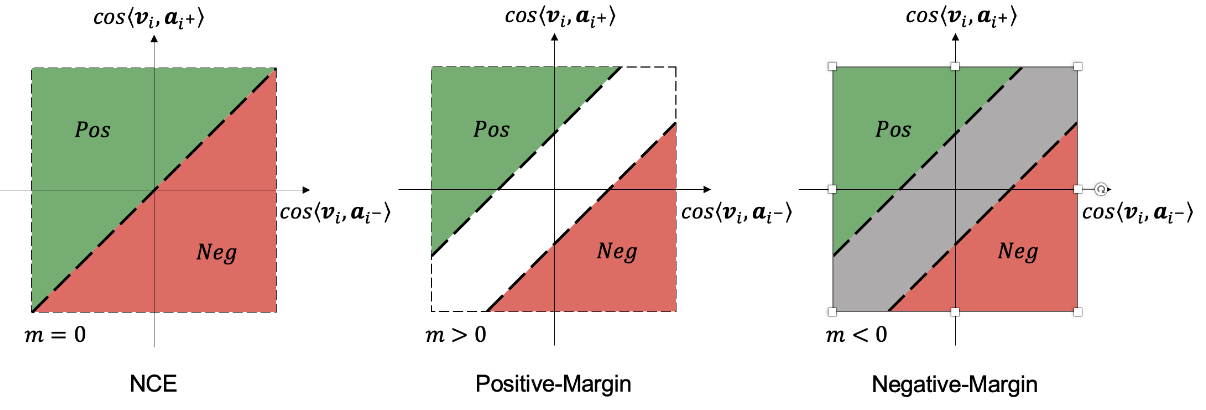
MarginNCE: Robust Sound Localization with a Negative Margin
Sooyoung Park*, Arda Senocak*, Joon Son Chung
ICASSP 2023 (* Equal Contribution)
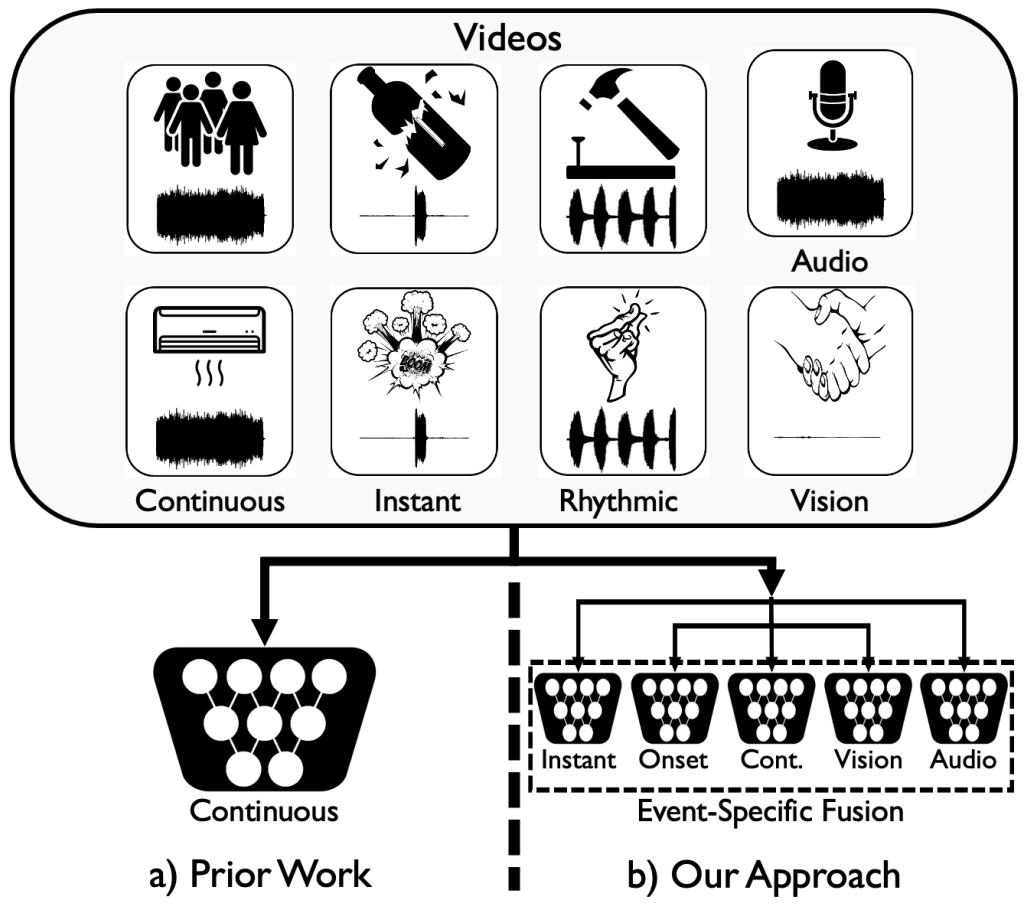
Event-Specific Audio-Visual Fusion Layers: A Simple and New Perspective on Video Understanding
Arda Senocak*, Junsik Kim*, Tae-Hyun Oh, Dingzeyu Li, In So Kweon
WACV 2023 (* Equal Contribution)
2022
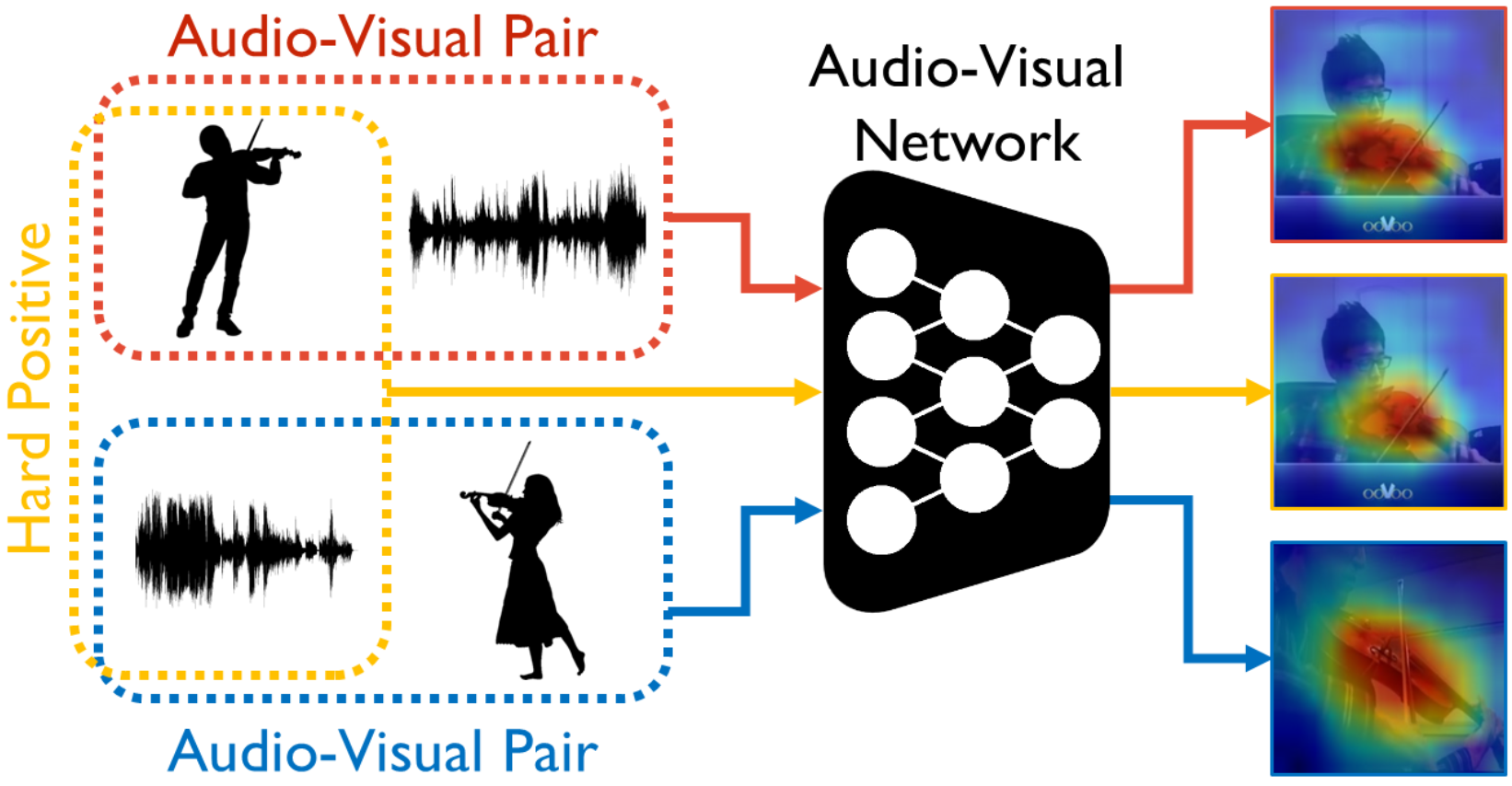
Learning Sound Localization Better from Semantically Similar Samples
Arda Senocak*, Hyeonggon Ryu*, Junsik Kim*, In So Kweon
ICASSP 2022 Oral (* Equal Contribution)
Short Version at Sight and Sound Workshop @ CVPR 2022
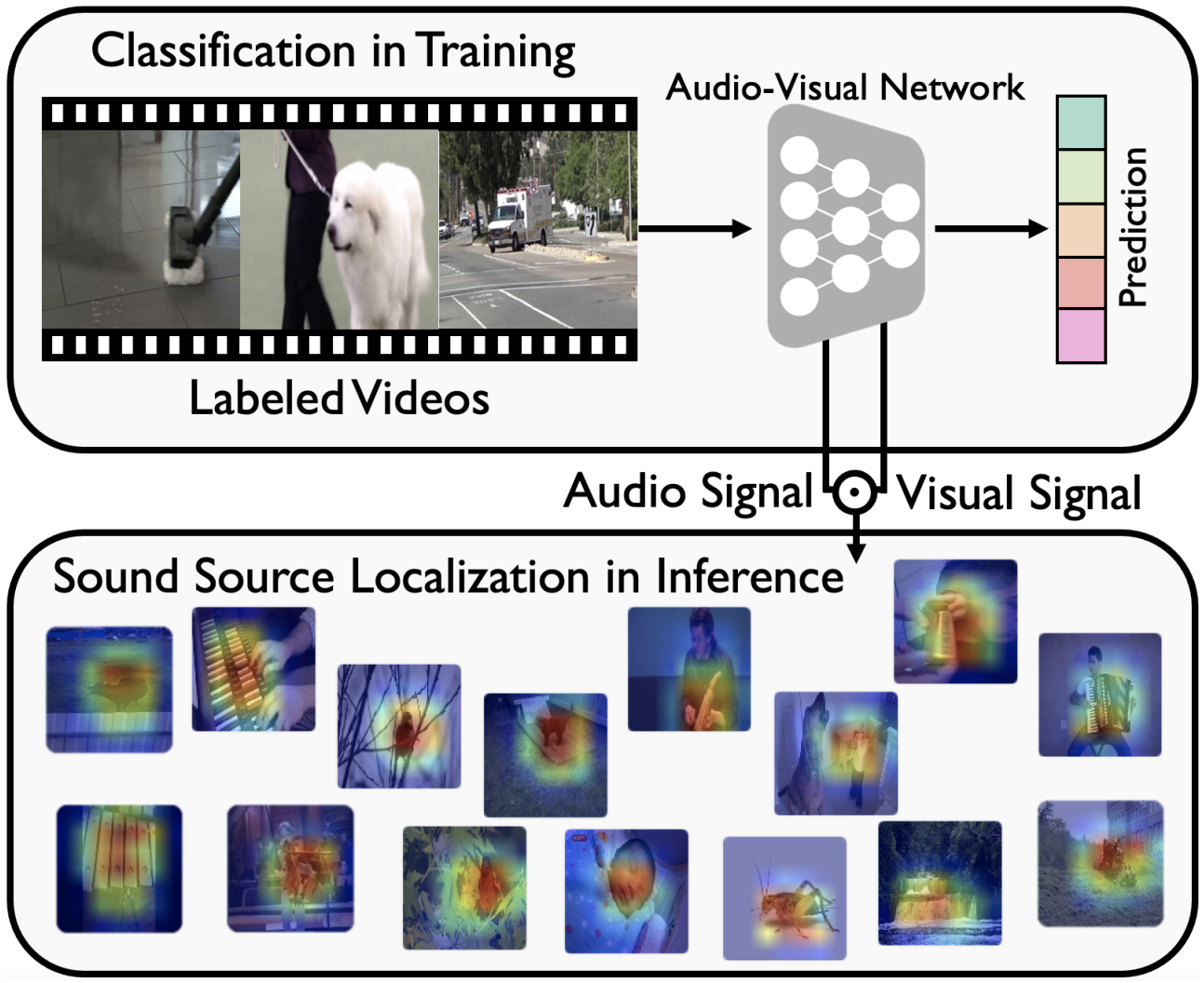
Less Can Be More: Sound Source Localization With a Classification Model
Arda Senocak*, Hyeonggon Ryu*, Junsik Kim*, In So Kweon
WACV 2022 (* Equal Contribution)
Received Honorable Mention, 28th HumanTech Paper Award, Samsung Electronics Co., Ltd. ($2000)
2021
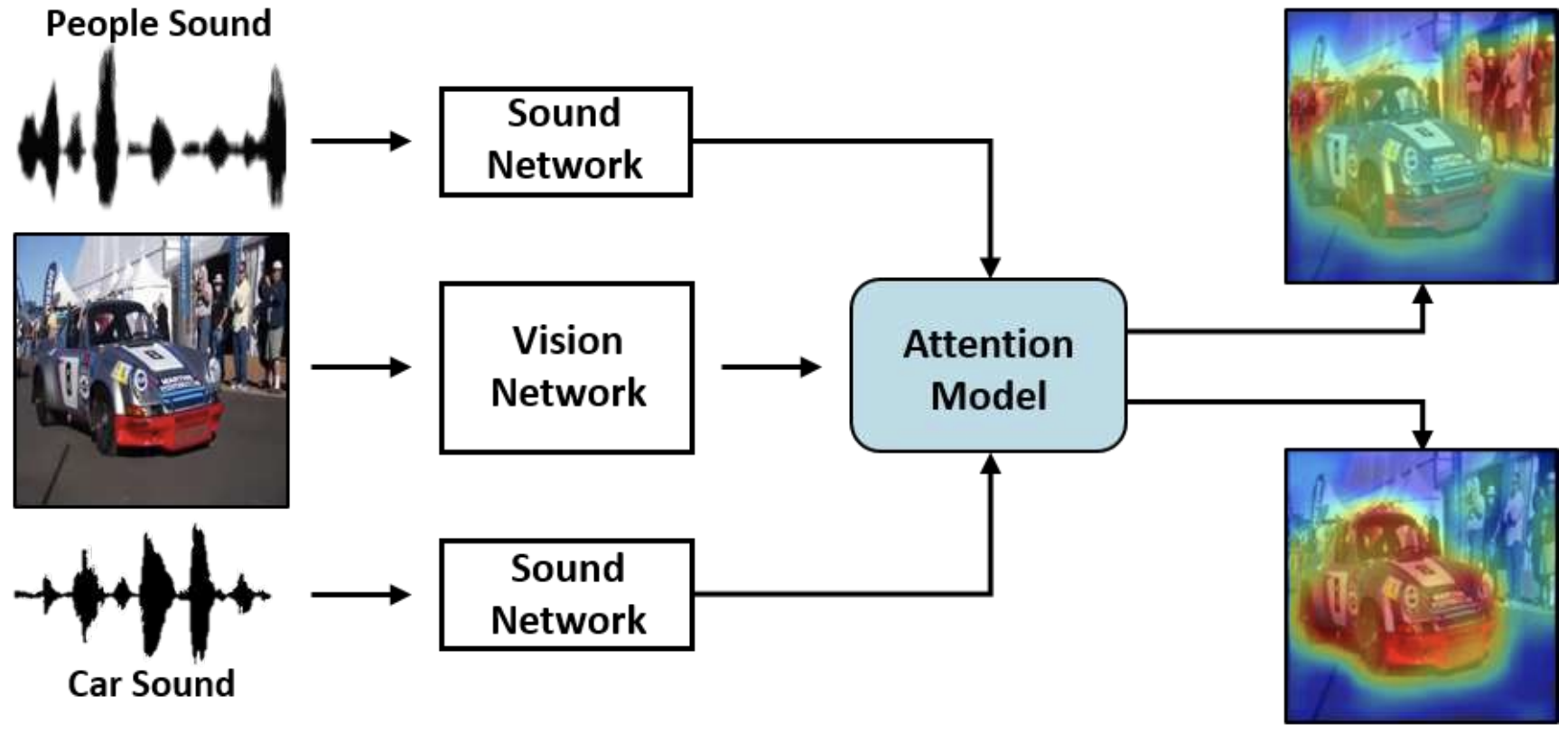
Learning to Localize Sound Source in Visual Scenes: Analysis and Applications
Arda Senocak, Tae-Hyun Oh, Junsik Kim, Ming-Hsuan Yang, In So Kweon
TPAMI 2021 Impact Factor: 24.314
2018
Learning to Localize Sound Source in Visual Scenes
Arda Senocak, Tae-Hyun Oh, Junsik Kim, Ming-Hsuan Yang, In So Kweon
CVPR 2018
Part-based Player Identification using Deep Convolutional Representation and Multi-scale Pooling
Arda Senocak, Tae-Hyun Oh, Junsik Kim, In So Kweon
CVSports Workshop @CVPR 2018